import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import seaborn.objects as so
import statsmodels.api as sm
import statsmodels.formula.api as smf
import itertools
import glob, os, warnings
from sklearn.model_selection import ParameterGrid
from scipy.stats import chi2
import random
random.seed(90059)Power Simulation in a Mixed Effects design using Python
In this notebook we’ll go through a quick example of setting up a power analysis, using data from an existing, highly-powered study to make credible parameter estimates. The code for setting up a simulation is inspired by/shamelessly stolen from a great tutorial about this topic by DeBruine & Barr (2021) and Lisa DeBruine’s appendix on its application for sensitivity analysis (DeBruine & Barr, 2020). The aim of this tutorial is two-fold:
- To demonstrate this approach for the most basic mixed model (using it only to deal with repeated measures - no nesting, no crossed random effects with stimuli types, etc.) which is a very common use of the technique for researchers in my immediate environment (visual attention research).
- To translate this approach to different languages - although I love R and encourage everyone to use it for statistical analysis, Python remains in use by a sizeable number of researchers, and I would also like to introduce Julia as an alternative.
Before we do anything, let’s import all the packages we will need:
In this example, we will make an estimate of the number of participants we need to replicate a simple and well-established experimental finding: The capture of attention by a colour singleton during visual search for a unique shape singleton. For this example, we are fortunate in that there are many studies of this effect for us to base our parameter estimates on. One recent example is a highly-powered study by Kirsten Adam from the Serences lab purpose-built to be used for sensitivity analysis. First let’s import the data for our specific case from the Adam et al. (2021) study, which is freely available in an OSF repository, and look at the data.
Note that when previous data doesn’t exist (or even if it does, but you don’t trust that it’s sufficient to base your effect estimates on) there are alternative ways of determining such parameters, including formally determining a smallest effect size of interest Lakens et al. (2018).
The data we chose is from experiment 1c: variable colour singleton search. We are interested in the raw trial data, not the summary data (We are doing a mixed model after all, not an ANOVA) so we have to grab all the raw files and concatenate them.
path = os.path.join(os.getcwd(),"Experiment_1c")
all_files = glob.glob(os.path.join(path, "*.csv"))
df = pd.concat((pd.read_csv(f) for f in all_files), ignore_index=True)Once it’s imported, we can take a look at our data, e.g., looking at subject means between the two conditions:
d = (df
.query("acc==1 & set_size==4")
.assign(rt = lambda x: x.rt * 1000)
.astype({'subject': 'str'}))
sns.set_theme()
sns.catplot(
data=d,
x="distractor",
y="rt",
hue="subject",
kind="point",
legend=False
)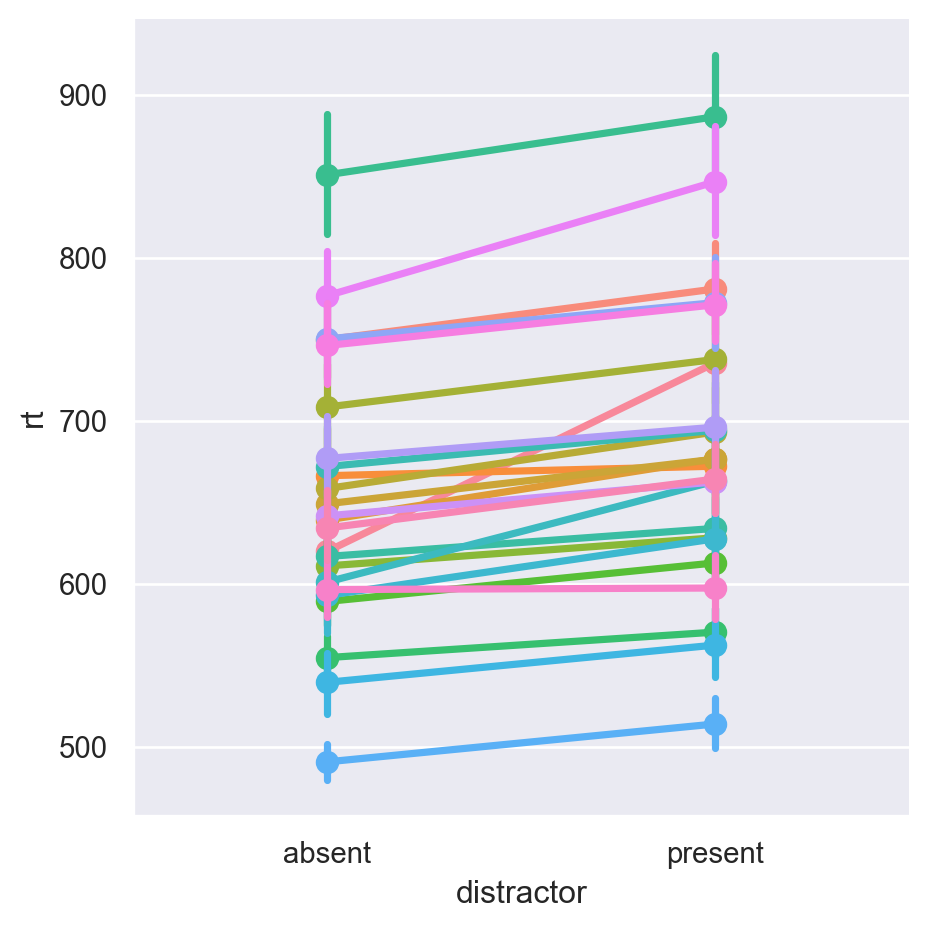
We can clearly see typical atttentional capture effects in the data. Now that we have the data, let’s model it:
# Our model is simple: RT is dependent on distractor presence, with a random slope and intercept for each subject. More complex models are left as an exercise to the reader.
md = smf.mixedlm("rt ~ distractor", d, groups=d['subject'],re_formula="~distractor")
md_null = smf.mixedlm("rt ~ 1", d, groups=d['subject'],re_formula="~distractor")
# We fit lmms with ML rather than REML to obtain the p-value of the likelihood ratio test for inclusion of a fixed effect (which is preferable over the default Wald test used by mixedlm to estimate significance)
m_lrt = md.fit(reml=False)
m_null_lrt = md_null.fit(reml=False)
lrt = 1 - chi2.cdf(-2*(m_null_lrt.llf - m_lrt.llf), 1)
print(f'A likelihood ratio test estimates the p-value for the inclusion of a coefficient for the presence of a singleton distractor to be {lrt}')
# Whereas for better estimates of the random effects' variance, we fit lmms with reml
m1 = md.fit()
m1.summary()A likelihood ratio test estimates the p-value for the inclusion of a coefficient for the presence of a singleton distractor to be 5.657725046237516e-07| Model: | MixedLM | Dependent Variable: | rt |
| No. Observations: | 9164 | Method: | REML |
| No. Groups: | 24 | Scale: | 30910.5844 |
| Min. group size: | 353 | Log-Likelihood: | -60427.4618 |
| Max. group size: | 395 | Converged: | Yes |
| Mean group size: | 381.8 |
| Coef. | Std.Err. | z | P>|z| | [0.025 | 0.975] | |
| Intercept | 651.500 | 16.663 | 39.098 | 0.000 | 618.841 | 684.159 |
| distractor[T.present] | 30.857 | 4.753 | 6.493 | 0.000 | 21.542 | 40.171 |
| Group Var | 6501.876 | 11.192 | ||||
| Group x distractor[T.present] Cov | 416.478 | 2.281 | ||||
| distractor[T.present] Var | 218.053 | 0.912 |
The above model rt ~ distractor + ( distractor | subject) is our putative data generating process, the parameters that we believe underly the generation of observed dependent variables, and the relationship between those parameters. The table shown above gives us parameter estimates for all fixed and random effects in the model. Now let’s plug those parameters into a simulation!
n_subj = 10 # number of subjects
n_present = 200 # number of distractor present trials
n_absent = 200 # number of distractor absent
beta_0 = 650 # Intercept
beta_1 = 30 # effect of distractor presence
tau_0 = 80 # by-subject random intercept sd
tau_1 = 15 # by-subject random slope sd
rho = 0.35 # correlation between intercept and slope
sigma = 175 # residual noseGenerate trials with their fixed effects:
# simulate a sample of items
# total number of items = n_ingroup + n_outgroup
items = (pd
.DataFrame({
'distractor' : np.repeat(['absent', 'present'], [n_absent, n_present])})
.assign(X_i=lambda x: np.where(x["distractor"] == 'present', 1, 0)))
items.describe()| X_i | |
|---|---|
| count | 400.000000 |
| mean | 0.500000 |
| std | 0.500626 |
| min | 0.000000 |
| 25% | 0.000000 |
| 50% | 0.500000 |
| 75% | 1.000000 |
| max | 1.000000 |
And generate participants with their random intercepts and slopes:
# simulate a sample of subjects
# calculate random intercept / random slope covariance
covar = rho * tau_0 * tau_1
# put values into variance-covariance matrix
cov_mx = np.array([
[tau_0**2, covar],
[covar, tau_1**2]
])
# generate the by-subject random effects
subject_rfx = np.random.multivariate_normal(mean = [0, 0], cov = cov_mx, size = n_subj)
# combine with subject IDs
subjects = pd.DataFrame({
'subj_id': range(n_subj),
'T_0s': subject_rfx[:,0],
'T_1s': subject_rfx[:,1]
})
subjects.describe()| subj_id | T_0s | T_1s | |
|---|---|---|---|
| count | 10.00000 | 10.000000 | 10.000000 |
| mean | 4.50000 | -26.274448 | 1.966927 |
| std | 3.02765 | 59.296125 | 17.573954 |
| min | 0.00000 | -99.178355 | -24.390412 |
| 25% | 2.25000 | -67.843592 | -10.747805 |
| 50% | 4.50000 | -25.059013 | 1.755718 |
| 75% | 6.75000 | -6.514674 | 14.298668 |
| max | 9.00000 | 93.768882 | 29.063208 |
Now combine and add residual noise to create a complete dataframe:
#cross items and subjects, add noise
items['key'] = 1
subjects['key'] = 1
trials = (pd
.merge(items,subjects, on='key')
.drop("key",axis=1)
.assign(e_si = lambda x: np.random.normal(scale=sigma,size=len(x))))
# calculate the response variable
dat_sim = (trials
.assign(RT = lambda x: beta_0 + x.T_0s + (beta_1 + x.T_1s) * x.X_i + x.e_si)
.filter(items=['subj_id', 'distractor', 'X_i', 'RT']))
dat_sim.head(10)| subj_id | distractor | X_i | RT | |
|---|---|---|---|---|
| 0 | 0 | absent | 0 | 574.209160 |
| 1 | 1 | absent | 0 | 734.397934 |
| 2 | 2 | absent | 0 | 725.764019 |
| 3 | 3 | absent | 0 | 408.048664 |
| 4 | 4 | absent | 0 | 653.636917 |
| 5 | 5 | absent | 0 | 464.147242 |
| 6 | 6 | absent | 0 | 787.649394 |
| 7 | 7 | absent | 0 | 455.787476 |
| 8 | 8 | absent | 0 | 417.752336 |
| 9 | 9 | absent | 0 | 406.035982 |
Data generated! Does it look like we’d expect?
sns.catplot(
data=dat_sim.astype({"subj_id": "string"}),
x="distractor",
y="RT",
hue="subj_id",
kind="point",
legend=False
)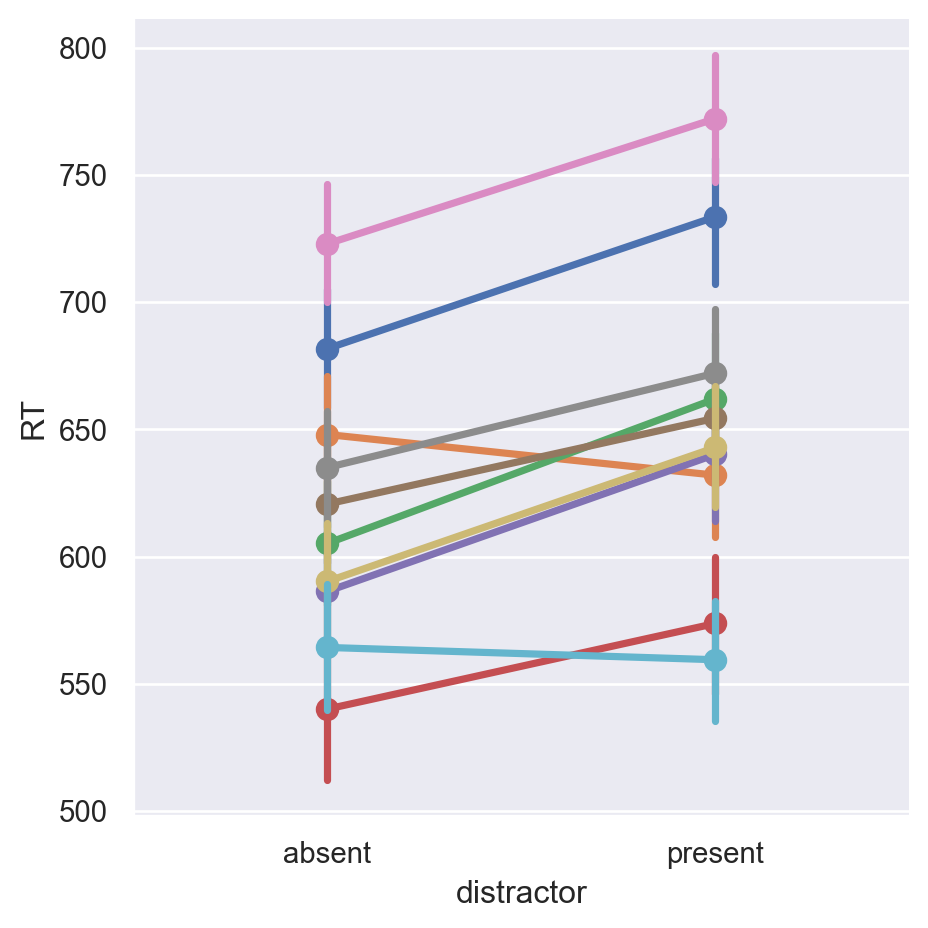
Looks comparable to the original data! Now let’s fit a model to see if we recover the parameters:
md = smf.mixedlm("RT ~ distractor", dat_sim, groups=dat_sim['subj_id'], re_formula="~distractor")
mdf = md.fit()
mdf.summary()| Model: | MixedLM | Dependent Variable: | RT |
| No. Observations: | 4000 | Method: | REML |
| No. Groups: | 10 | Scale: | 31572.5832 |
| Min. group size: | 400 | Log-Likelihood: | -26409.7559 |
| Max. group size: | 400 | Converged: | Yes |
| Mean group size: | 400.0 |
| Coef. | Std.Err. | z | P>|z| | [0.025 | 0.975] | |
| Intercept | 619.466 | 17.367 | 35.670 | 0.000 | 585.428 | 653.504 |
| distractor[T.present] | 34.785 | 8.041 | 4.326 | 0.000 | 19.025 | 50.545 |
| Group Var | 2858.133 | 8.013 | ||||
| Group x distractor[T.present] Cov | 374.642 | 2.652 | ||||
| distractor[T.present] Var | 330.865 | 1.718 |
Great, our simulation works - we recover our ground truth for the different coefficients (allowing for differences due to noise and limited sample size). Now for a power analysis, we’d put the above in functions and run the code many times for a given combination of parameters. See below:
def my_sim_data(
n_subj = 5, # number of subjects
n_present = 200, # number of distractor present trials
n_absent = 200, # number of distractor absent
beta_0 = 650, # Intercept
beta_1 = 30, # effect of distractor presence
tau_0 = 80, # by-subject random intercept sd
tau_1 = 15, # by-subject random slope sd
rho = 0.35, # correlation between intercept and slope
sigma = 175 # residual noise
):
# simulate a sample of items
# total number of items = n_ingroup + n_outgroup
items = (pd.DataFrame({
'distractor' : np.repeat(['absent', 'present'], [n_absent, n_present])
})
.assign(X_i=lambda x: np.where(x["distractor"] == 'present', 1, 0)))
# simulate a sample of subjects
# calculate random intercept / random slope covariance
covar = rho * tau_0 * tau_1
# put values into variance-covariance matrix
cov_mx = np.array([
[tau_0**2, covar],
[covar, tau_1**2]
])
# generate the by-subject random effects
subject_rfx = np.random.multivariate_normal(mean = [0, 0], cov = cov_mx, size = n_subj)
# combine with subject IDs
subjects = pd.DataFrame({
'subj_id': range(n_subj),
'T_0s': subject_rfx[:,0],
'T_1s': subject_rfx[:,1]
})
#cross items and subjects, add noise
items['key'] = 1
subjects['key'] = 1
trials = (pd
.merge(items,subjects, on='key').drop("key",axis=1)
.assign(e_si = lambda x: np.random.normal(scale=sigma,size=len(x))))
# calculate the response variable
dat_sim = (trials
.assign(RT = lambda x: beta_0 + x.T_0s + (beta_1 + x.T_1s) * x.X_i + x.e_si)
.filter(items=['subj_id', 'distractor', 'X_i', 'RT']))
return dat_simThe above function simulates data. The function below combines it with a model fit so we have a function that can be repeatedly called during our power analysis.
def single_run(filename = None, *args, **kwargs):
dat_sim = my_sim_data(*args, **kwargs)
with warnings.catch_warnings(record=True) as w:
warnings.simplefilter("ignore")
md = smf.mixedlm("RT ~ distractor", dat_sim, groups=dat_sim['subj_id'], re_formula="~distractor")
md_null = smf.mixedlm("RT ~ 1", dat_sim, groups=dat_sim['subj_id'], re_formula="~distractor")
# As above, we use the LRT method to obtain a better estimate of the coefficient's significance. This does mean we're fitting 2 models every sim - consider switching to the default p-values (so removing the null model definition, fit, the lrt calculation, and the line that replaces the p-value) if this takes too long (psst, or switch to Julia)
mod_sim = md.fit(reml=False)
mod_sim_null = md_null.fit(reml=False)
lrt = 1 - chi2.cdf(-2*(mod_sim_null.llf - mod_sim.llf),1)
sim_results = (mod_sim
.summary()
.tables[1]
.assign(**kwargs))
sim_results = sim_results.apply(pd.to_numeric, errors='coerce')
sim_results.index.rename('i',inplace=True)
sim_results.at[1,'P>|z|'] = lrt
if not filename == None:
hdr = not os.path.isfile(filename)
sim_results.to_csv(filename, mode='a',header=hdr)
return sim_resultsNow let’s run our sensitivity analysis - we will run our simulation many times (100 times here for speed, but aim for more, like 1000+) for each combination of parameters, and record how often the fixed effect estimates reach significance:
nreps = 100
params = ParameterGrid({
'n_subj' : [7], # number of subjects
'n_present' : [150], # number of distractor present trials
'n_absent' : [150], # number of distractor absent
'beta_0' : [650], # Intercept
'beta_1' : [30], # effect of distractor presence
'tau_0' : [80], # by-subject random intercept sd
'tau_1' : [15], # by-subject random slope sd
'rho' : [0.35], # correlation between intercept and slope
'sigma' : [175] # residual (standard deviation)
})
sims = pd.concat([single_run(**param) for param in params for i in range(nreps)])
alpha = 0.05
(sims
.assign(power = sims['P>|z|'] < alpha)
.query('i=="Intercept" or i=="distractor[T.present]"')
.groupby(['i'])
.agg(
mean_estimate = ('Coef.','mean'),
mean_se = ('Coef.', 'sem'),
power = ('power', 'mean')))| mean_estimate | mean_se | power | |
|---|---|---|---|
| i | |||
| Intercept | 650.89476 | 3.329489 | 1.00 |
| distractor[T.present] | 30.25037 | 0.941347 | 0.84 |
If we want to run our sensitivity analysis across a given parameter space, we’ll have to map the function single_run to generate data across this space, for example, over a varying number of participants:
filename1 = "sens_py.csv"
nreps = 1000
params = ParameterGrid({
'n_subj' : range(2,15), # number of subjects
'n_present' : [150], # number of distractor present trials
'n_absent' : [150], # number of distractor absent
'beta_0' : [650], # Intercept
'beta_1' : [30], # effect of category
'tau_0' : [80], # by-subject random intercept sd
'tau_1' : [15], # by-subject random slope sd
'rho' : [0.35], # correlation between intercept and slope
'sigma' : [175] # residual (standard deviation)
})
if not os.path.isfile(filename1):
# run a simulation for each row of params
# and save to a file on each rep
sims1 = pd.concat([single_run(**param, filename=filename1) for param in params for i in range(nreps)])Note that the above could obviously also be run over other dimensions of our parameter space, e.g. for different estimates of the fixed effects, amount of noise, number of trials, etc. etc., by changing the params list. How did we do? Let’s take a look at our power curve.
sims1 = pd.read_csv('sens_py.csv')
power1 = (sims1.assign(power = sims1['P>|z|'] < alpha)
.query('i=="distractor[T.present]"')\
.groupby(['n_subj'])\
.agg(
mean_estimate = ('Coef.','mean'),
mean_se = ('Coef.', 'sem'),
power = ('power', 'mean')))sns.regplot(x=power1.index, y=power1["power"],lowess=True)
plt.axhline(y=.8)<matplotlib.lines.Line2D at 0x1fd28b5cdf0>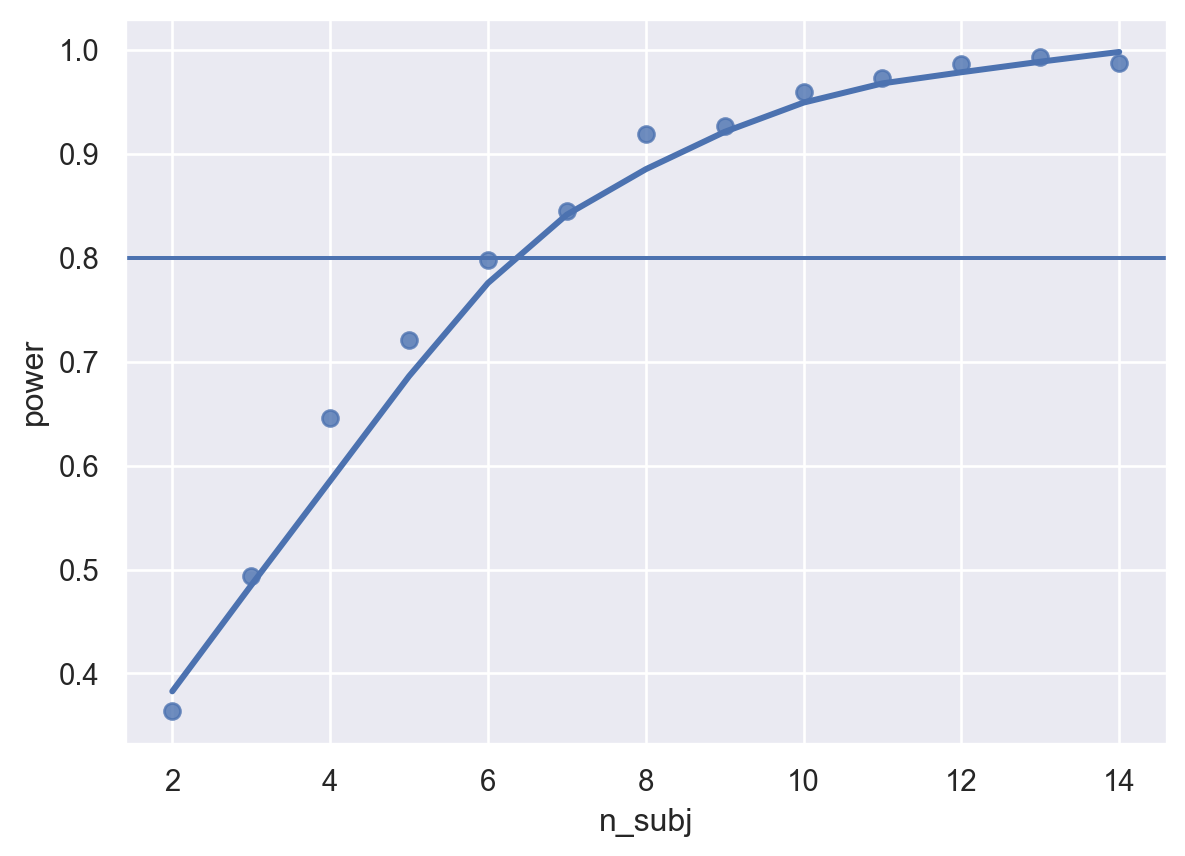
Our power analysis has determined that, with the parameters established above, we need ~8 or more participants to reliably detect an effect!
The code used above is specific to power analysis for mixed models, but the approach generalises to other methods too, of course! The above code can easily be wrangled to handle different model types (simply change the model definition in single_run and make sure to capture the right parameters), and even Bayesian approaches. (For a thorough example of doing power analysis with Bayesian methods and the awesome bayesian regression package brms, see Kurz, 2021.)
Even if the above code is spaghetti to you (Perhaps you prefer R? or Julia?), I hope you will take away a few things from this tutorial:
- Power analysis is nothing more than testing whether we can recover the parameters of a hypothesised data-generating process reliably using our statistical test of choice.
- We can determine the parameters for such a data-generating process in the same way we formulate hypotheses (and indeed, in some ways these two things are one and the same): we use our knowledge, intuition, and previous work to inform our decision-making.
- If you have a hypothetical data-generating process, you can simulate data by simply formalising that process as code and letting it simulate a dataset
- Simulation can help you answer questions about your statistical approach that are difficult to answer with other tools
References
Adam, K. C. S., Patel, T., Rangan, N., & Serences, J. T. (2021). Classic Visual Search Effects in an Additional Singleton Task: An Open Dataset. 4(1), 34. https://doi.org/10.5334/joc.182
DeBruine, L. M., & Barr, D. J. (2020). Appendix 1c: Sensitivity Analysis. https://debruine.github.io/lmem_sim/articles/appendix1c_sensitivity.html.
DeBruine, L. M., & Barr, D. J. (2021). Understanding Mixed-Effects Models Through Data Simulation. Advances in Methods and Practices in Psychological Science, 4(1), 2515245920965119. https://doi.org/10.1177/2515245920965119
Kurz, A. S. (2021). Bayesian power analysis: Part I. Prepare to reject ‘\(H_0\)‘ with simulation. In A. Solomon Kurz. https://solomonkurz.netlify.app/blog/bayesian-power-analysis-part-i/.
Lakens, D., Scheel, A. M., & Isager, P. M. (2018). Equivalence Testing for Psychological Research: A Tutorial. Advances in Methods and Practices in Psychological Science, 1(2), 259–269. https://doi.org/10.1177/2515245918770963